Java中JVM字节码的详细介绍
来源:不言 发布时间:2018-10-10 16:18:23 阅读量:1840
本篇文章给大家带来的内容是关于Java中JVM字节码的详细介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
这是Java基础篇(JVM)的文章,本来想先说说Java类加载机制的,后来想想,JVM的作用是加载编译器编译好的字节码,并解释成机器码,那么首先应该了解字节码,然后再谈加载字节码的类加载机制似乎会好些,所以这篇改成详解字节码。
由于Java纯面向对象的特性,字节码只要能表示一个类的信息,就可以表示整个Java程序了,JVM只要能加载一个类的信息,就能加载整个程序了。所以,不管是字节码,还是JVM加载机制,关注点都是在类。我关注的点主要在于:
1. 由于字节码不是一次性全部加载进入内存,那么JVM是如何知道自己要加载的类信息在.class文件的哪个位置的?
2. 字节码是如何表示类信息的?
3. 字节码会进行程序的优化吗?
第一个问题很简单,因为哪怕一个源文件有很多个类(只有一个public类),编译器也会为其中每个类都生成一个.class文件,JVM加载时按照需要加载的类名称加载即可。
要解决后面的问题,首先我们来看字节码的组成(Mac下用Hex Fiend打开)。
对这样一段代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
我们来分析其中的Extend类。
用Hex Fiend打开编译后的.class文件是这样的(16进制代码):
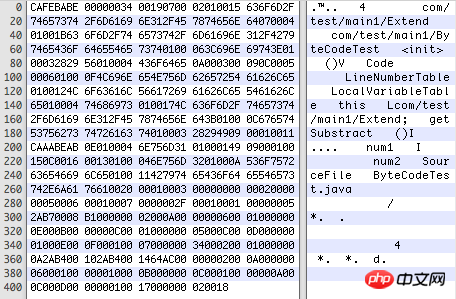
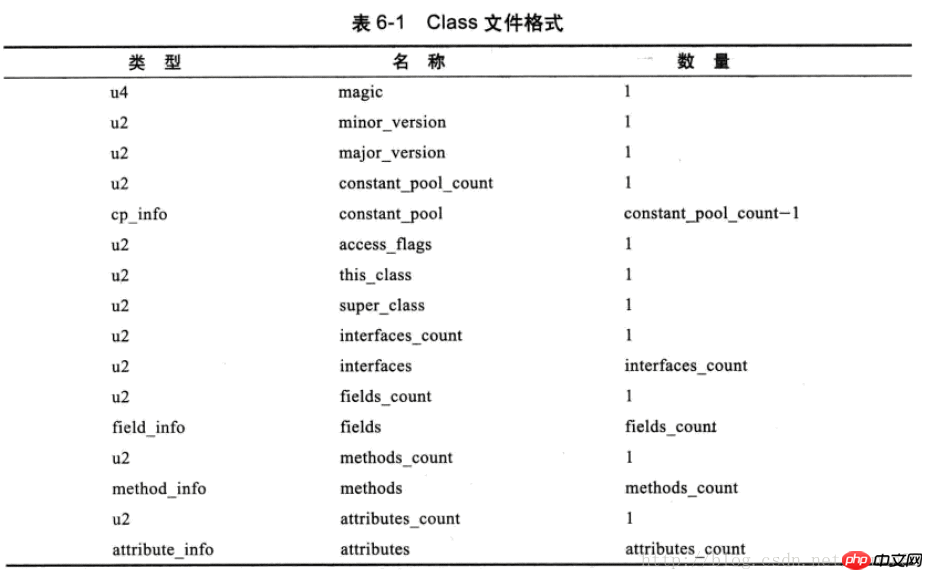
由于class文件没有分隔符,所以每个位置代表什么、各个部分的长度等格式是严格规定死的,见下表:
其中u1、u2、u4、u8代表几个字节的无符号数,在反编译出来的16进制文件中,两个数字代表一个字节,也就是u1。
从头到尾一项一项地看:
(1)magic:u4,魔数,代表本文件是.class文件。.jpg等也会有这种魔数,正因为魔数存在,即使将*.jpg改成*.123,也能照常打开。
(2)minor version、major version:各u2,版本号,向下兼容,即高版本JDK可以使用低版本的.class文件,反之不行。
(3)constant_pool_count:u2,常量池中常量的数量,0019代表有24个。
(4)接下来就是具体的常量,共constant_pool_count-1个。
常量池通常存两种类型的数据:
字面量:如字符串、final修饰的常量等;
符号引用:如类/接口的全限定名、方法的名称和描述、字段的名称和描述等。
根据反编译出来的数字,首先查下表得到该常量的类型和长度,接下来的与查得的长度相等的数字则表示该常量具体的值。
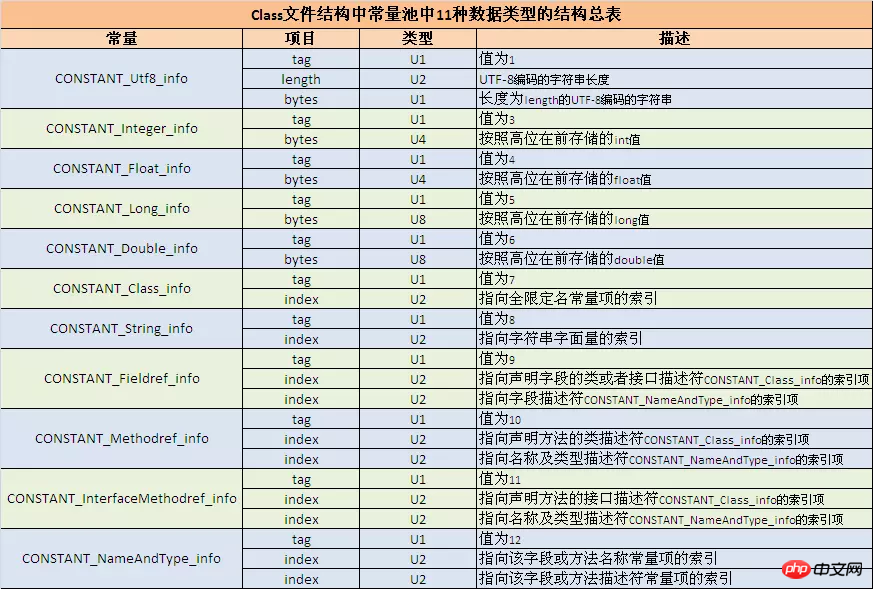
如070002,就表示该种类型为CONSTANT_Class_info,它的tag为u1,且接下来u2长度为index指向全限定名常量项的索引。这个索引还要结合javap -verbose打开的class文件一起看,这里清晰地列出了常量池中的内容和顺序:
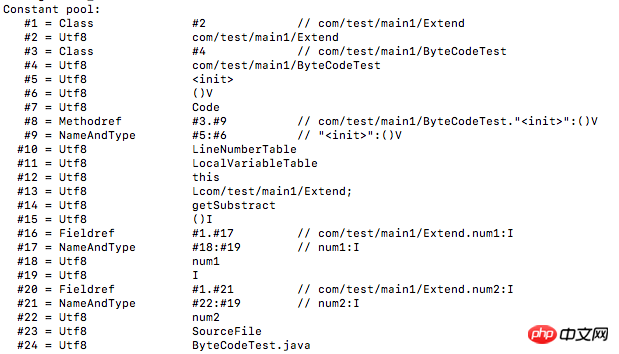
在这里可以看到0002索引项的常量为:com/test/main1/Extend,是类的全限定名。如果是值是字符串,那么需要根据该值转换成十进制并查ASCII码表得到具体的字符。接下来的常量都照此分析:
01001563 6F6D2F74 6573742F 6D61696E 312F4578 74656E64:com/test/main1/Extend
070004:com/test/main1/ByteCodeTest
01001B63 6F6D2F74 6573742F 6D61696E 312F4279 7465436F 64655465 7374:com/test/main1/ByteCodeTest
0100063C 696E6974 3E:<init>
01000328 2956:()V
01000443 6F6465:Code
0A000300 09:com/test/main1/ByteCodeTest、"<init>":()V
0C000500 06:<init>、()V
01000F4C 696E654E 756D6265 72546162 6C65:LineNumberTable
0100124C 6F63616C 56617269 61626C65 5461626C 65:LocalVariableTable
01000474 686973:this
0100174C 636F6D2F 74657374 2F6D6169 6E312F45 7874656E 643B:Lcom/test/main1/Extend;
01000C67 65745375 62737472 616374:getSubstract
01000328 2949:()I
09000100 11:com/test/main1/Extend、num1:I
0C001200 13:num1、I
0100046E 756D31:num1
01000149:I
09000100 15:com/test/main1/Extend、num2:I
0C001600 13:num2、I
0100046E 756D32:num2
01000A53 6F757263 6546696C 65:SourceFile
01001142 79746543 6F646554 6573742E 6A617661:ByteCodeTest.java
至此,常量池中的常量全部解析完毕。
(5)再接下来是u2的access_flags:access_flags访问标志的主要目的是标记该类是类还是接口,如果是类,访问权限是否为public,是否是abstract,是否被标志为final等,见下表:
| Flag_name | Value | Interpretation |
| ACC_PUBLIC | 0x0001 | 表示访问权限为public,可以从本包外访问 |
| ACC_FINAL | 0x0010 | 表示由final修饰,不允许有子类 |
| ACC_SUPER | 0x0020 | 较为特殊,表示动态绑定直接父类,见下面的解释 |
| ACC_INTERFACE | 0x0200 | 表示接口,非类 |
| ACC_ABSTRACT | 0x0400 | 表示抽象类,不能实例化 |
| ACC_SYNTHETIC | 0x1000 | 表示由synthetic修饰,不在源代码中出现,见附录[2] |
| ACC_ANNOTATION | 0x2000 | 表示是annotation类型 |
| ACC_ENUM | 0x4000 | 表示是枚举类型 |
所以,本类中的access_flags是0020,表示这个Extend类调用父类的方法时,并非是编译时绑定,而是在运行时搜索类层次,找到最近的父类进行调用。这样可以保证调用的结果是一定是调用最近的父类,而不是编译时绑定的父类,保证结果的正确性。
(6)this_class:u2的类索引,用于确定类的全限定名。本类的this_class是0001,表示在常量池中#1索引,是com/test/main1/Extend
(7)super_class:u2的父类索引,用于确定直接父类的全限定名。本类是0003,#3是com/test/main1/ByteCodeTest
(8)interfaces_count:u2,表示当前类实现的接口数量,注意是直接实现的接口数量。本类中是0000,表示没有实现接口。
(9)Interfaces:表示接口的全限定名索引。每个接口u2,共interfaces_count个。本类为空。
(10)fields_count:u2,表示类变量和实例变量总的个数。本类中是0000,无。
(11)fields:fileds的长度为filed_info,filed_info是一个复合结构,组成如下:
1 2 3 4 5 6 7 |
|
由于本类无类变量和实例变量,故本字段为空。
(12)methods_count:u2,表示方法个数。本类中是0002,表示有2个。
(13)methods:methods的长度为一个method_info结构:
1 2 3 4 5 6 7 |
|
其中attribute_info结构如下:
1 2 3 4 5 |
|
上面是通用的attribute_info的定义,另外,JVM里预定义了几种attribute,Code即是其中一种(注意,如果使用的是JVM预定义的attribute,则attribute_info的结构就按照预定义的来),其结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
LineNumberTable和LocalVariableTable又是两个预定义的attribute,其结构如下:
1 2 3 4 5 6 7 8 |
|
以及:
1 2 3 4 5 6 7 8 9 10 |
|
然后就是第二个方法,具体略过。
(14)attributes_count:u2,这里的attribute表示整个class文件的附加属性,和前面方法的attribute结构相同。本类中为0001。
(15)attributes:class文件附加属性,本类中为0017,指向常量池#17,为SourceFile,SourceFile的结构如下:
1 2 3 4 5 |
|
嗯,字节码的内容大概就写这么多。可以看到通篇文章基本都是在分析字节码文件的16进制代码,所以可以这么说,字节码的核心在于其16进制代码,利用规范中的规则去解析这些代码,可以得出关于这个类的全部信息,包括:
1. 这个类的版本号;
2. 这个类的常量池大小,以及常量池中的常量;
3. 这个类的访问权限;
4. 这个类的全限定名、直接父类全限定名、类的直接实现的接口信息;
5. 这个类的类变量和实例变量的信息;
6. 这个类的方法信息;
7. 其它的这个类的附加信息,如来自哪个源文件等。
解析完字节码,回头再来看开始提出的问题,也就迎刃而解了。由于字节码文件格式严格按照规定,可以用来表示类的全部信息;字节码只是用来表示类信息的,不会进行程序的优化。
那么在编译期间,编译器会对程序进行优化吗?运行期间JVM会吗?什么时候进行的,按照什么原则呢?这个留作以后再表。
最后,值得注意的是,字节码不仅是平台无关的(任何平台生成的字节码都可以在任何的JRE环境运行),还是语言无关的,不仅Java可以生成字节码,其它语言如Groovy、Jython、Scala等也能生成字节码,运行在JRE环境中。

 13450931319
13450931319 微信登录
微信登录
 QQ登录
QQ登录
 微博登录
微博登录


 售前咨询
售前咨询
