时序数据库连载系列: RISElab的大杀器Confluo
来源:转载 发布时间:2019-02-23 16:57:29 阅读量:2074
挑战
随着越来越多的应用达到每秒千万级的数据点采集能力,比如终端IoT网络监控,智能家居,数据中心等等。 并且这些数据被应用于在线查询展示,监控,离线根因分析和系统优化。 这些场景要求系统具备高速写入,低延迟的在线查询以及低开销的离线查询的能力。 然而已有的数据结构很难满足这些要求。有些数据结构侧重与高速的写入和简单的查询, 有些则侧重于复杂的查询,比如即席查询,离线查询,雾化视图等等,增加了维护开销,牺牲了写入的性能。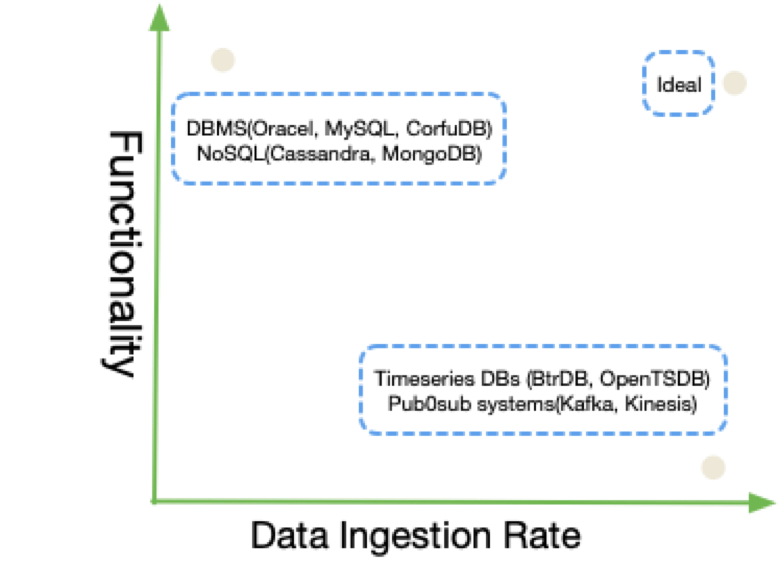
为了解决这些挑战,Confluo应运而生。
前提和典型应用场景
Confluo之所以可以同时实现几个挑战目标,是因为在一些场景上做了取舍。一个典型的场景是遥感数据
这些遥测数据有以下几个非常重要的特点:
- write-once: 数据追加写,无更新和删除
- 定长的数据类型
- 并发场景下没有事务,只保证原子性
针对这些数据特点,Confluo实现了一个创新型数据结构来实现高吞吐,在线/离线查询。
特性
Confluo面向实时监控和数据流分析场景,比如网络监控和诊断框架,时序数据库,pub-sub的消息系统,主要特性包括:
- 百万级数据点高并发写入
- 毫秒级在线查询
- 占用很少的的CPU资源实现即席查询
实现概要
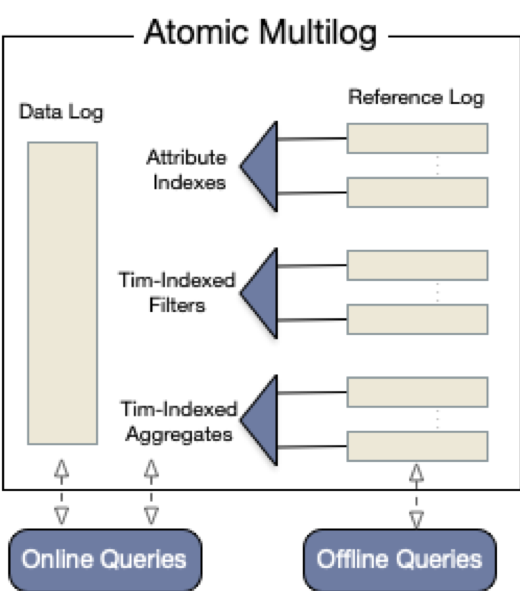
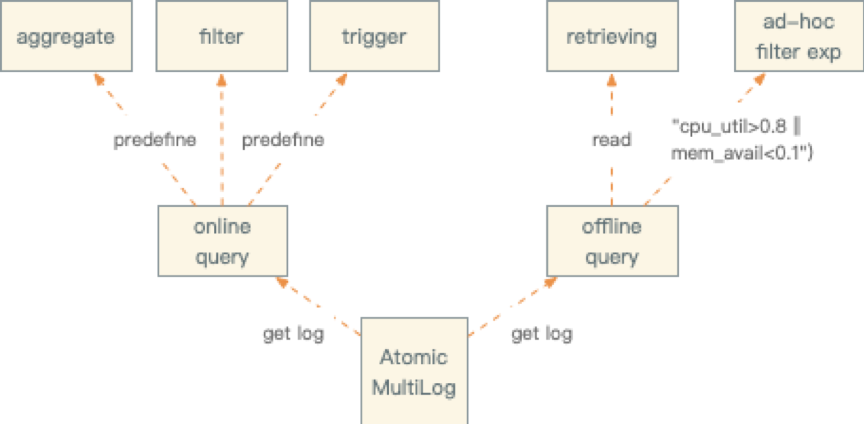
Confluo的基本存储抽象是新型的数据结构”Atomic MultiLog“,后面文章简称“AM”, AM依赖于2个关键性技术:
- AM是无锁并发日志集合,可以用来存储原始数据,聚合统计,雾化视图。每一个日志记录writeTail和readTail并发读写。
- 日志更新采用现代CPU硬件支持的原子指令集:AtomicLoad,AtomicStore,FetchAndAdd,CompareAndSwap
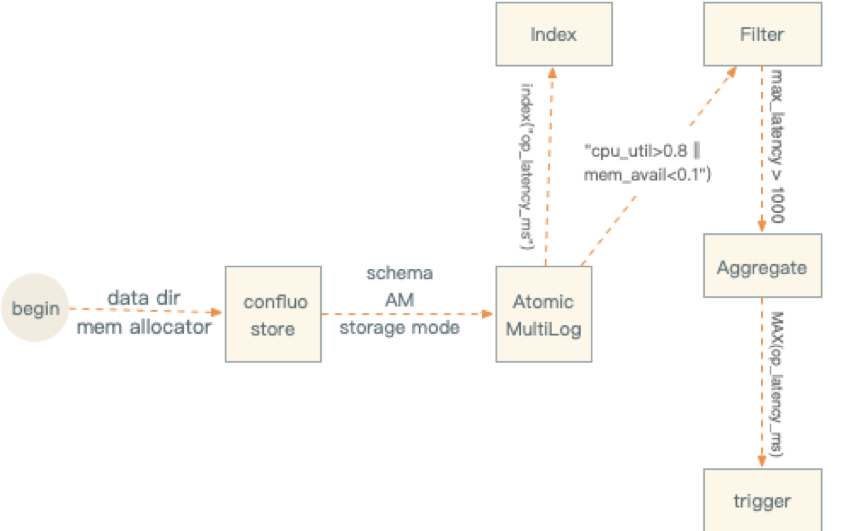
AM在接口方面同数据库的表类似,所以应用在使用时首先创建一个固定schema的AM对象。然后按照这个schema写入数据流。并且创建索引(index),过滤器(filter),聚合器(aggregate)以及触发器(trigger)等等用于监控和诊断。
Confluo 数据模型
- Confluo的数据模型是强类型集合。
- 原生数据类型:BOOL, CHAR, SHORT, INT, LONG, FLOAT, DOUBLE, STRING.
{ timestamp: ULONG, op_latency_ms: DOUBLE, cpu_util: DOUBLE, mem_avail: DOUBLE, log_msg: STRING(100) }- 时间戳8个字节,如果应用没有写入时间戳,Confluo会内置添加时间戳。
- 指标数据包含double类型以及string类型。
- 自定义类型。自定义类型通过实现属性字段,注册接口,类型获取接口后,就可以作为schema的成员建立数据模型,追加数据以及执行filter,trigger等操作。
写入
- 创建存储数据的Store File
- 创建具有固定Schema的AM AM有3种存储模式:IN_MEMORY, DURABLE, DURABLE_RELAXED
- IN_MEMORY:所有的数据存储在内存中。
- DURABLE:类似写穿的方式,数据持久化到磁盘
- DURABLE_RELAXED:数据在内存中缓存,周期性持久化。
- 执行AM基本操作。 AM定义了Index,Filter, Aggregate, trigger
- 添加Index, 应用层可以为每一个指标建立K叉树索引.
- 添加Filter, filter 由关系和布尔运算符组成,应用于指标的过滤.
操作符 | 示例 |
等于 | dst_port=80 |
范围 | cpu_util>.8 |
与 | volt>200 && temp>100 |
或 | cpu_util>.8 mem_avail<.1 |
不等于 | transport_protocol != TCP |
- 添加Aggregate:适用于filter之后的记录聚合,比如: SUM,MIN,MAX,COUNT,AVG
- 添加Trigger:是一个布尔条件,适用于结果集上的操作 比如:MAX(latency_ms) > 100
查询
Confluo既可以离线查询也可以实时查询,区别在于是否要预定义规则。
- 离线查询主要面向诊断分析,如果fExpressio已经定义,增直接查看FilterLog,否则通过IndexLog方式查询原始数据。
- 实时流式查询主要面向实时监控和报警,需要预定义规则。比如通过定义triggers实现报警能力,类似SUM(pktSize)>1GB的报警规则定义。
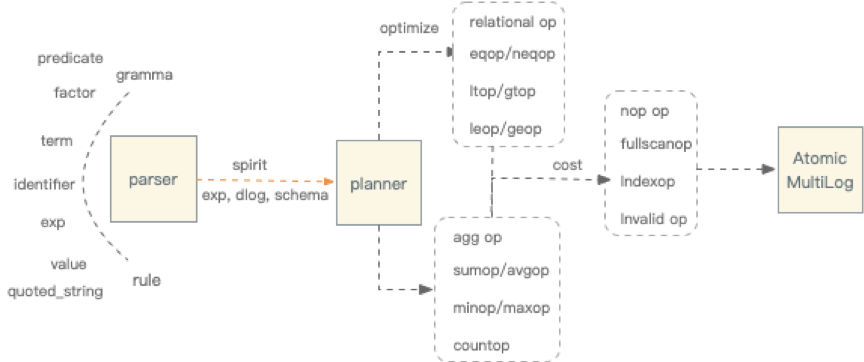
- 解析器:语法解析的实现采用了spirit.对于这类小型符合EBNF语法规范的数据模型,spirit还是比较灵活。Confluo定义了exp,term,factor,predicate,identificate, value, quoted_string等几种语法规则.
- 执行计划:解析器生成表达式后,通过查询计划器生成执行计划为agg->filter->index。Confluo内置了一个简单的评估器,根据近似count计算cost判断走index或者full scan。
数据归档和压缩
Confluo除了存储原始数据,同时需要存储索引,预定义的过滤,聚合等等,因此这些数据带来了存储开销的膨胀。通过引入归档方式把部分数据存储到冷设备,从而解决这一问题。目前支持3种数据归档方式:周期性的归档,强制性的归档,基于内存的归档。
- 周期性的归档。 默认情况下,每5分钟数据会归档一次。后台归档管理任务周期性检测AM日志配置的大小,一旦超过限制DataLog,IndexLog,FilterLog会归档到冷设备存储。
- 强制性的归档 无论归档是否开启,用户都可以调用接口强制性归档。 接口上既支持全量归档,也支持基于偏移量的增量归档。
- 基于内存的归档 当周期性归档持续低于高速写入的数据量时内存会溢出,为避免这种情况,引入基于内存大小的归档机制。当系统内存达到自定义的阈值时,内存分配被阻塞,直到所有的AM归档到冷数据。
- 编码 归档时HeaderLog默认采用LZ4压缩,IndexLog和FilterLog采用Delta压缩。 解压在读取的时候由底层引擎完成,通过引用计数避免归档线程与读取线程之间的并发性访问。
核心技术点
Atomic MultiLog
Atomic MultiLog是整个系统的核心技术点。主要包括DataLog,IndexLog, FilterLog, AggregateLog以及如何原子性的操作这些日志。
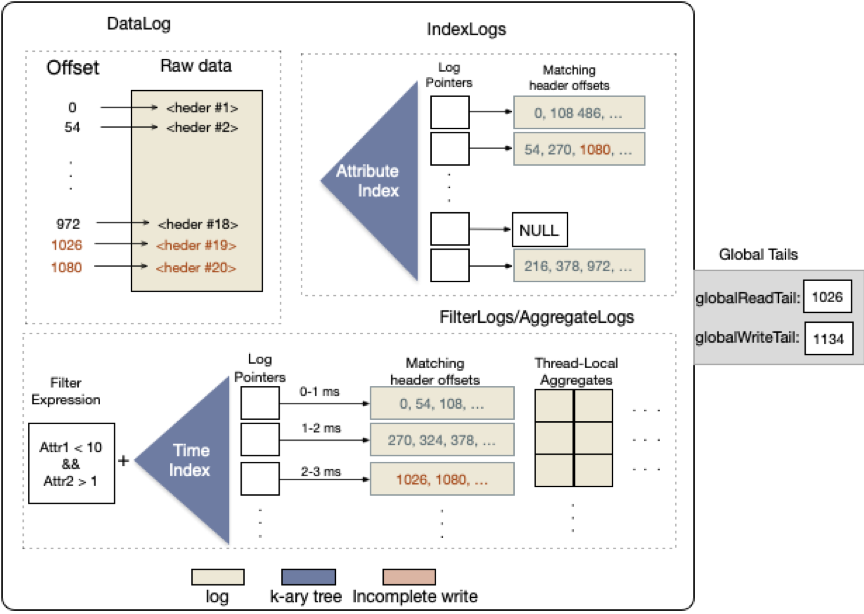
- DataLog 分为2部分offset和原始数据点,offset是原始数据的唯一标识。
- IndexLog 是datalog的索引部分,采用radix树组织索引,radix树是通用的字典类型数据结构,比如在监控场景中的IP地址,网络地址有大量的prefix是可以共享的。
- FilterLog 存储了基于时间窗口切分的原始数据offset,按照radix树索引filter和窗口。
- AggregateLog 同其它日志相似,也是基于时间分片的索引数据方式。由于聚合日志需要读后写,设计了thread-local的集合来保证安全访问。
集成方式:
Confluo是一个开源C++项目。有2种集成模式:
- 可以作为嵌入式的依赖库,支持在线和离线分析。
- 可以作为独立的服务,对外暴露RPC接口通信。
总结
大名鼎鼎的riseLab新鲜出炉的Confluo,核心创新在于数据结构Atomic MultiLog,可以支持高速并发读写,单核可以运行1000个trigger,10个Filter。非常好的一个闪光点,找到某个特定业务场景,采用新硬件的原子操作和无锁日志做到了实时,离线,高速写入的统一。
标签:
数据库
评论:
你还没有登录,请先登录

 13450931319
13450931319 微信登录
微信登录
 QQ登录
QQ登录
 微博登录
微博登录


 售前咨询
售前咨询
